# SLM Lab
Modular Deep Reinforcement Learning framework in PyTorch.
Companion library of the book Foundations of Deep Reinforcement Learning.
GitHub · Benchmark Results
{% hint style="info" %}
**NOTE:** v5.0 updates to Gymnasium, `uv` tooling, and modern dependencies with ARM support—see [Changelog](/slm-lab/resources/changelog.md).
**Book readers:** use `git checkout v4.1.1` for the book code. See [book website and errata](https://slm-lab.gitbook.io/foundations-of-deep-rl/).
{% endhint %}
| | | | |
| :------------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------------------------------: |
|  |  |  | 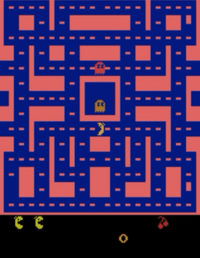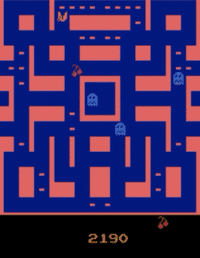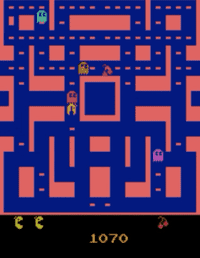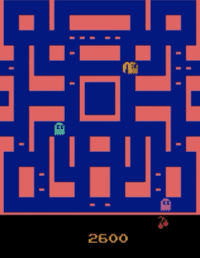 |
| BeamRider | Breakout | KungFuMaster | MsPacman |
|  |  |  |  |
| Pong | Qbert | Seaquest | Sp.Invaders |
|  |  | 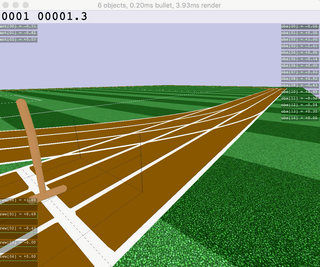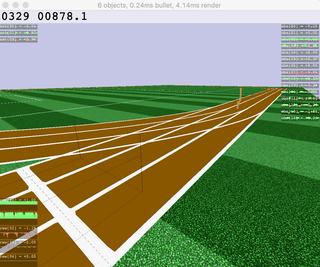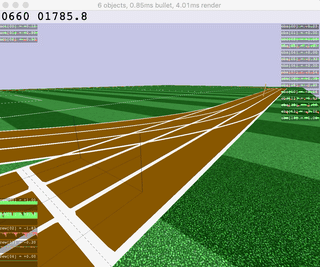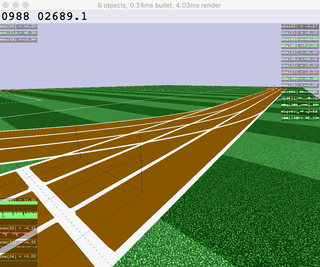 |  |
| Ant | HalfCheetah | Hopper | Humanoid |
|  |  |  |  |
| Inv.DoublePendulum | InvertedPendulum | Reacher | Walker |
SLM Lab is a software framework for **reinforcement learning** (RL) research and application in PyTorch. RL trains agents to make decisions by learning from trial and error—like teaching a robot to walk or an AI to play games.
## What SLM Lab Offers
| Feature | Description |
| --------------------------- | ------------------------------------------------------------------- |
| **Ready-to-use algorithms** | PPO, SAC, CrossQ, DQN, A2C, REINFORCE—validated on 70+ environments |
| **Easy configuration** | JSON spec files fully define experiments—no code changes needed |
| **Reproducibility** | Every run saves its spec + git SHA for exact reproduction |
| **Automatic analysis** | Training curves, metrics, and TensorBoard logging out of the box |
| **Cloud integration** | dstack for GPU training, HuggingFace for sharing results |
## Algorithms
SLM Lab implements the canonical RL algorithms with a [taxonomy-based inheritance](/slm-lab/development/modular-lab-components/algorithm-taxonomy.md) design:
| Algorithm | Type | Best For | Validated Environments |
| ---------------- | ---------- | ----------------------- | -------------------------------------------------------- |
| **REINFORCE** | On-policy | Learning/teaching | Classic |
| **SARSA** | On-policy | Tabular-like | Classic |
| **DQN/DDQN+PER** | Off-policy | Discrete actions | Classic, Box2D, Atari |
| **A2C** | On-policy | Fast iteration | Classic, Box2D, Atari (57) |
| **PPO** | On-policy | General purpose | Classic, Box2D, MuJoCo (11), Atari (57), Playground (54) |
| **SAC** | Off-policy | Continuous + discrete | Classic, Box2D, MuJoCo, Atari (48) |
| **CrossQ** | Off-policy | Fast continuous control | Classic, Box2D, MuJoCo |
See [Benchmark Results](/slm-lab/benchmark-results/public-benchmark-data.md) for detailed performance data.
## Environments
SLM Lab uses [Gymnasium](https://gymnasium.farama.org/) (the maintained fork of OpenAI Gym):
| Category | Examples | Difficulty | Docs |
| --------------------- | ------------------------------------------------- | --------------- | ------------------------------------------------------------------------------- |
| **Classic Control** | CartPole, Pendulum, Acrobot | Easy | [Gymnasium Classic](https://gymnasium.farama.org/environments/classic_control/) |
| **Box2D** | LunarLander, BipedalWalker | Medium | [Gymnasium Box2D](https://gymnasium.farama.org/environments/box2d/) |
| **MuJoCo** | Hopper, HalfCheetah, Humanoid | Hard | [Gymnasium MuJoCo](https://gymnasium.farama.org/environments/mujoco/) |
| **Atari** | Qbert, MsPacman, and 54 more | Varied | [ALE](https://ale.farama.org/environments/) |
| **MuJoCo Playground** | DM Control Suite, Locomotion Robots, Manipulation | GPU-accelerated | [MuJoCo Playground](https://google-deepmind.github.io/mujoco_playground/) |
Any gymnasium-compatible environment works—just specify its name in the spec. [MuJoCo Playground](https://google-deepmind.github.io/mujoco_playground/) environments use JAX/MJWarp GPU simulation and are specified with the `playground/` prefix.
## Citation
If you use SLM Lab in your publication, please cite:
```
@misc{kenggraesser2017slmlab,
author = {Keng, Wah Loon and Graesser, Laura},
title = {SLM Lab},
year = {2017},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/kengz/SLM-Lab}},
}
```
## License
This project is licensed under the [MIT License](https://github.com/kengz/SLM-Lab/blob/master/LICENSE).
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://slm-lab.gitbook.io/slm-lab/readme.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.